Two problems with your logic:
1) A view is an action, not a person.
2) International viewers can view the URL even if there is much less of a chance it will be relevant to their job search
In addition to what thephyber said, the Netflix culture doc has been very widely read across many industries as exemplary of a high performance culture. Similarly, I'm not in the shoe sales business but I've read the Zappos Core Values[0] as well.
Why don't Balanced and Stripe work together on these features? I understand that they're competitors, but it seems as though we've got good engineers in both companies needlessly duplicating effort. Why not work together to provide this feature and spend that limited engineering time, expertise, and innovation on the things which differentiate the service? Stripe and Balanced aren't direct competitors, I think - why not work together on the common ground and use the time saved to make the differences really shine?
[I think I'm being overly utopian, but I don't understand why. Can someone explain it to me?]
For the same reason most companies don't share trade secrets.
- Stripe and Balanced ARE direct competitors, much more so than say Stripe and Braintree or Balanced and PayPal. Balanced handles the money in a bit of a different way, but the end product is very similar (i.e. receive payments from cards and bank accounts, and send payments to bank accounts [and now debit cards for both as well]).
- One or both companies may feel they have the better solution (see steveklabnik's comment above), and thus collaborating would be giving away intellectual capital for less in return
As a potential customer, you should prefer that they do work separately, because when different teams come up with different solutions, the chances are greater that at least one of those solutions is correct. This leads to greater long-term health in the industry as a whole.
Read the "Founders at Work" chapter on Max Levchin and Paypal. In PayPal's early stages, there were multiple companies all trying to do online money transfers securely. They were all fighting fraud to the tune of millions of dollars daily. Eventually, PayPal was the first to figure out some ingenious ways to combat fraud. With the first reliable online money transfer network, they were able to dominate the market, especially on Ebay then the largest ecommerce site.
tl;dr - Winner-take-all market.
I was surprised too that he hadn't heard of JavaServer Faces, given that it's the One Official Web Framework of Java. I'm not sure I'd recommend it necessarily, but it's hugely popular and well-supported, so it knocks at least a couple of his criteria right out of the park.
Spring license mistake noticed (on the WP page it reads 'springsource', not apache 2.0!), as for JavaServer Faces, it may be extremely popular I just never ran into it in actual use and I see quite a few companies every year.
Is it somehow associated with a branch of industry that I don't have exposure to? Do you have some examples from the 100 top websites written using JavaServer Faces?
From what I know, JSF is used mostly for small to medium intranet application in the context of big enterprises.
I'm quite biased here, but the big seal of approval as the official java enterprise web framework makes it often imposed by the upper layer of the enterprise than a willing choice by the developers.
Additionally, if the enterprise is licensing a lot of oracle products, it's not surprising if they have a ADF (adf is a jsf implementation and component library) license with jdeveloper, which is trumpeted as the successor of oracle forms.
I hadn't previously read a description of St Louis quite like that - he makes it sound very appealing. Does anyone else have personal experience with living in St Louis?
We have a growing tech scene. Some of my friends refer to St. Louis's tech as the "Silicon Ghetto" as it's not quite as expansive as SF. More businesses are moving and starting up here because of Arch Grants and one of the co-founders of Square has a startup accelerator here as well.
Granted, I don't work for a company in St. Louis. I actually work remotely for a company based out of San Fran.
I think you're making an assumption: that pknight is correctly understanding your point and disagreeing with it out of a sense of entitlement to a date. I think he is misunderstanding your point, partially due to the word "tutorial", which to me indicates something ephemeral (something I'd want to have a date on), or the word "content", which can be interpreted any way. By failing to appreciate the cause of his disagreement, you exacerbate it with true-but-misplaced statements like "I don't owe it to you".
I think tptacek is thinking of content with longevity, such as essays - observations of human behavior, for example, wouldn't benefit much from a date. He's damaging his argument by calling them "tutorials", which you and I associate with learning particular tools which will soon be out-of-date.
The type of content does not matter, can you think of any significant written work pre-internet that purposely obfuscates when it was written? Even an encyclopedia isn't shy about when it's written.
If you want your content to appear valuable vs less valuable, write the hell out of your content. Make it impossible to discount the content by making it stand out.
In science, researchers don't cherry pick and refer studies written in the last 5 years. They go back as far is relevant. They will refer back to hallmark papers regardless how old. Same with nonfiction books. Same with well written blog posts, because good blog authors often cite references to give the proper context. That's kind of the point of blogging, the power of linking and building upon what has already written. But making a piece of content float in some unspecified time vortex disrupts that.
What's more is that a clear date indicates that the author wrote it at a certain time. It makes it harder to distinguish people that copy content or write about similar copycat ideas from their more original authors.
For what it's worth, I'm not against the idea of situating your content in the best way possible. I think using categorization like tutorials/articles/essays is a better way of framing certain types of content. That can help the reader. Hiding the date meta is an attempt to help the author, while hampering the reader. It doesn't even add up.
The encyclopaedia usually has its date prominently displayed on the cover because it's part of the business model: Nudging people into upgrading last year's edition because it's "hopelessly out of date".
Well, pre-internet our family only ever had 1 set and they retain a very high base value even as they age, never felt a need to update to a newer set continually.
Point still stands though, are PG's essays devalued because he puts a year date on them? I don't think so.
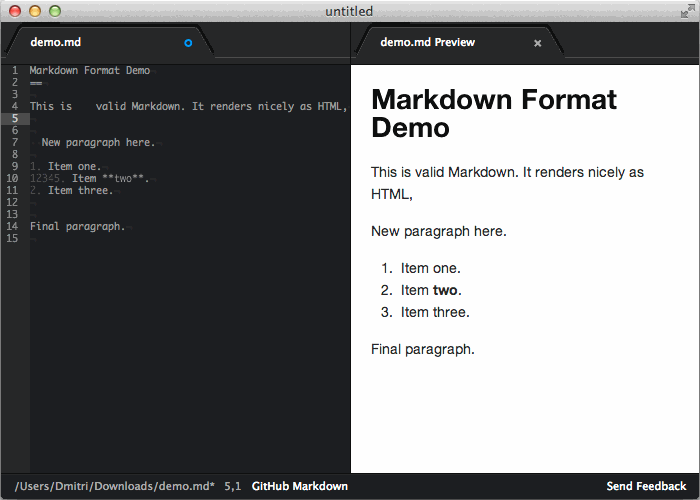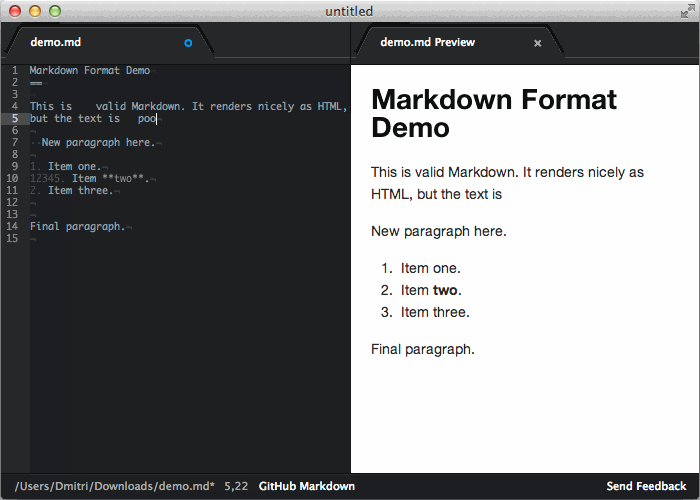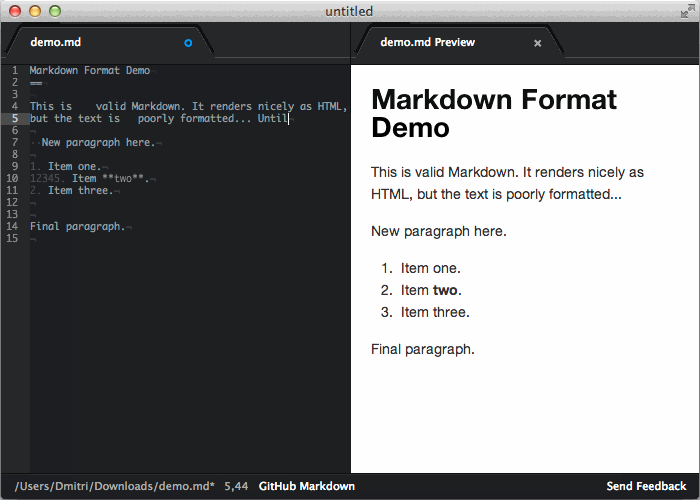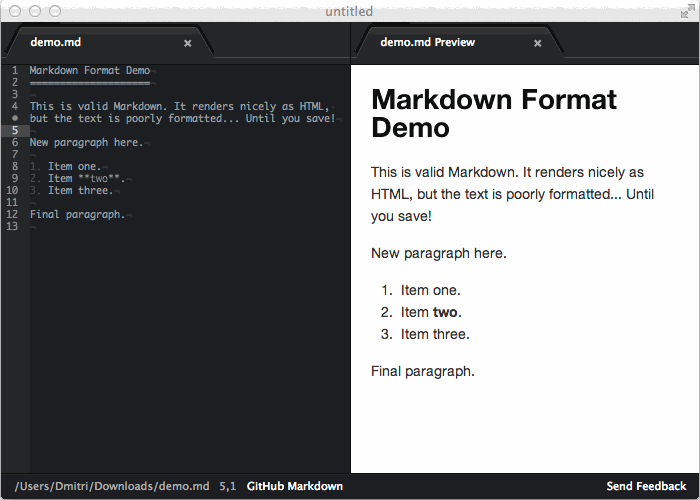
I can live with condensing numbered lists and removing the blank lines between items. Unwrapping plain text paragraphs is worse but not the end of the world. We start to toe the line with unwrapping my blockquotes. You went way past that line when you removed the empty line at the end of the file.
> Unwrapping plain text paragraphs is worse but not the end of the world. We start to toe the line with unwrapping my blockquotes.
What do you mean by "unwrapping"? Can you give an example please. I don't think it should be doing any unwrapping; blockquotes should be preserved (and nicely formatted) [1].
> You went way past that line when you removed the empty line at the end of the file.
It makes sure the last line has an ending newline, nothing more, nothing less. Any extra newlines are not visible in the generated HTML.
Alice wants to conduct a survey of her customers. She wants to restrict
access to her customers (ie select subset of people) and she wants
customers to be able to answer openly and not worry about reprisals.
> Is there a magic token that Alice can distribute to her customers
> (Bob,Carol,etc) that demonstrates their membership in survey pool and
> protects the anonymity of their responses?
Transcript:
dfc@ronin:~$ wc example.md
8 67 395 example.md
dfc@ronin:~$ .gopath/bin/markdownfmt example.md > gofmt.md
dfc@ronin:~$ wc gofmt.md
3 65 390 gofmt.md
dfc@ronin:~$ cat gofmt.md
Alice wants to conduct a survey of her customers. She wants to restrict a**SNIP**
> Is there a magic token that Alice can distribute to her customers (Bob,**SNIP**
dfc@ronin:~$
I truncated the lines in the cat gofmt.md because long preformatted colums kill HN readability. That file was 7 lines of pristine markdown with a trailing newline. markdownfmt turned it into three lines total.
I am not sure what you mean by "It makes sure the last line has an ending newline, nothing more, nothing less. Any extra newlines are not visible in the generated HTML." I thought this was a markdown formatting tool?
Here is a hypothetical--but common--workflow that this destroys: Author keeps multiple chapters of book in separate files for easy editing and revision control. When it is time to publish text the author executes:
> $ cat 1.md 2.md 3.md 4.md |publishmd --some-options
>
> You killed my chapter titles.
I did not consider such a use case. Currently, markdownfmt works on an individual file/stdin and considers that to be the entire Markdown; it does not know that you're planning to concatenate more files.
It would work fine if you passed `cat 1.md 2.md 3.md 4.md` as input, but removing excess newlines at the end of individual Markdown files will ruin the concatenated result.
It's similar to an issue that goimports also has [1].
I'll think about it, perhaps something can be done to solve this.
Is saying this is similar to an issue in goimport a sly way of saying markdownfmt "works on a file-by-file basis like gofmt; and as such it does not and cannot know that file a.go and b.go belong to the same package. Put another way, this is a user error for the tool as is."?
That explanation does not really make sense. I want markdownfmt to work on the file chapter1.md and the following day after editing chapter 2 I want to process chapter2.md. markdownfmt never needs to know and never will know that I use chapter1.md and chapter2.md together. When I am done I am going to feed chapter[1-X].md to another tool for publishing. But I cant because I used markdownfmt on a file by file basis and it damaged my files.
Every large book I have seen that uses markdown uses this chapter (or smaller) as file workflow. The biggest example that comes to mind is the progit book: https://github.com/progit/progit/tree/master/en
I understand the problem, I'm thinking how to best solve it.
FWIW, the markdown files for all chapters in that book you've linked do not contain an extra newline at the end; there's only one (just like markdownfmt leaves it).
What about using something like cat, except one that inserts a newline between all the files it concatenates? That way the .md files can remain as they are.
It's related to the decision of whether to enable EXTENSION_HARD_LINE_BREAK, which I've currently left off. So in order to start a new paragraph, you need to leave a empty line in between.
It assumes you're using automatic word wrapping in your editor to wrap the paragraphs (this works well if you resize your editor width, or type extra text in the middle of it - the text within the paragraph is reflowed automatically and doesn't go offscreen).
I can understand that's a deal-breaker for you if you're not willing to use word wrap in your editor.
People who are using Julia or similar tools to do "scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing" - what sort of problems are you solving? How did you end up doing this sort of work?
{kind=link}